RAG工程
1. RAG(检索增强生成)
RAG(Retrieval-Augmented Generation,检索增强生成) 就是实现上下文工程的强大技术方案。
核心思想:
-
检索:检索与私域知识相关的知识片段。
-
增强:与用户的问题合并喂给大模型。
-
生成:生成大模型返回的回答。
构建RAG主要为2个阶段:
1.1. 建立索引
建立索引是为了将私有知识文档或片段转换为可以高效检索的形式。通过将文件内容分割并转化为多维向量(使用专用 Embedding 模型),并结合向量存储保留文本的语义信息,方便进行相似度计算。向量化使得模型能够高效检索和匹配相关内容,特别是在处理大规模知识库时,显著提高了查询的准确性和响应速度。
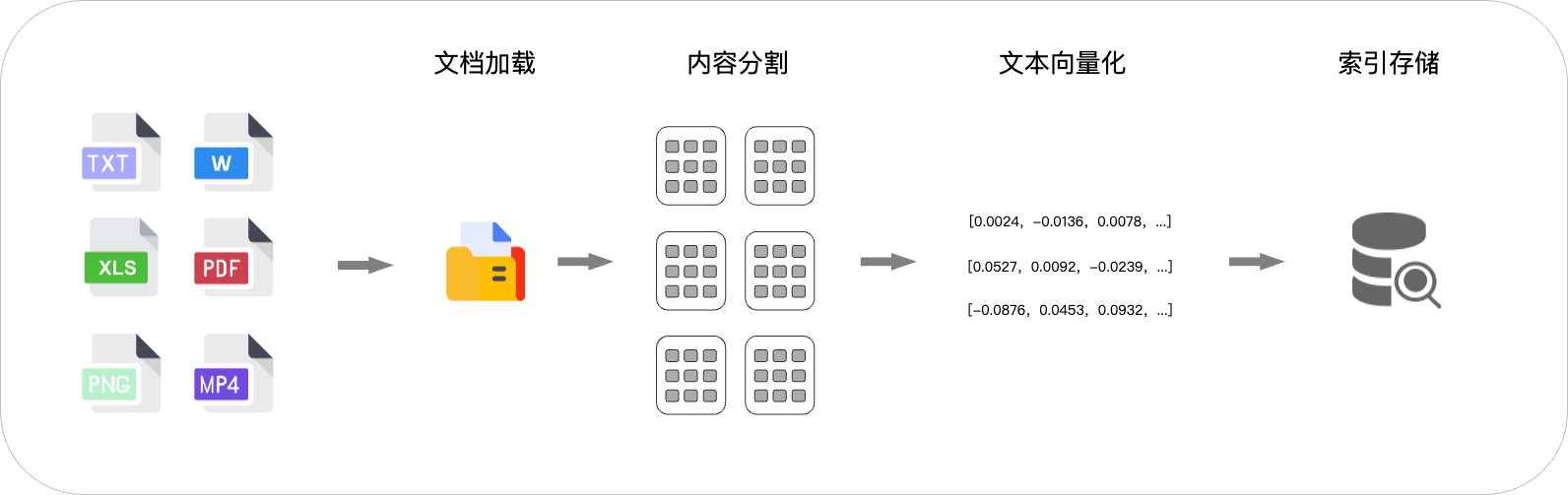
建议索引主要包含以下步骤:
-
文档解析:需要将各种格式的文档(pdf, word)解析成大模型可理解的格式。
-
文本分段:对解析后的文档进行分类分段,以便可以快速找到。
-
文本向量化:对文本进行数字化,以便进行相似度比较和寻址。
-
存储索引:将向量化后的数据存储到向量数据库,增加后续的查找速度。
1.2. 检索与生成
检索生成是根据用户的提问,从索引中检索相关的文档片段,这些片段会与提问一起输入到大模型生成最终的回答。这样大模型就能够回答私有知识问题了。
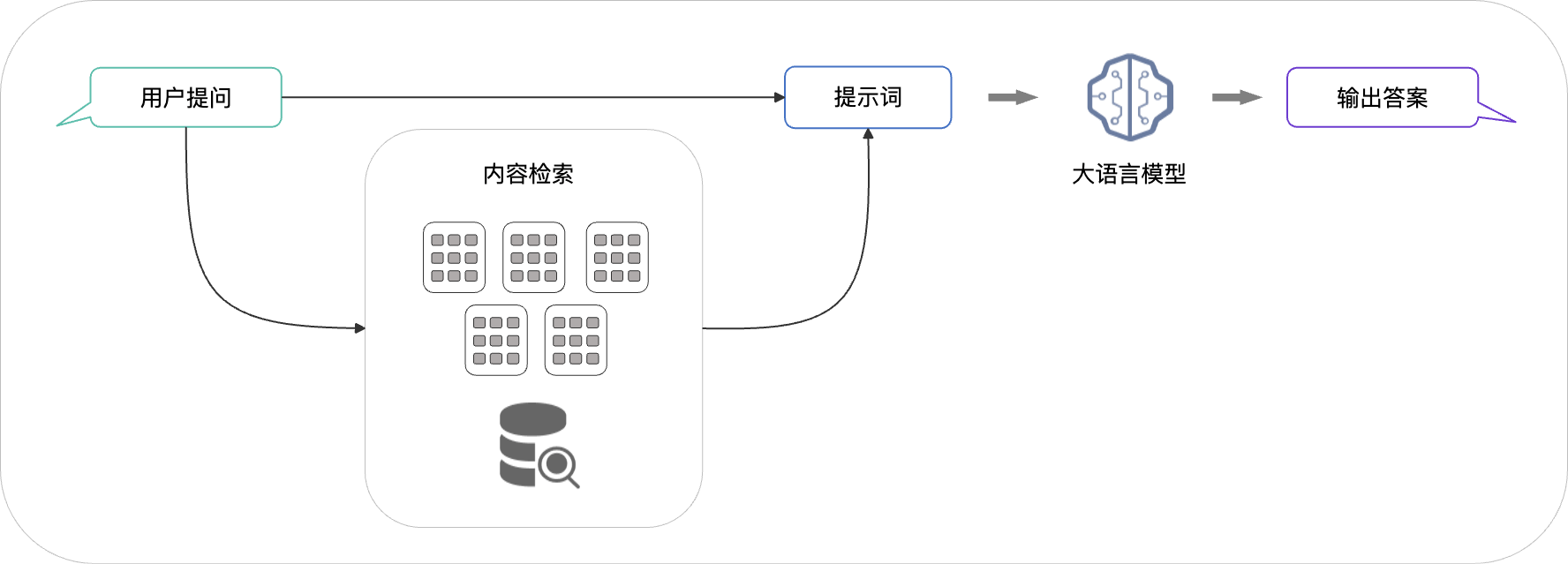
-
检索:检索会把问题同向量数据库的进行相似度比较,并找出最相关的段落。
-
生成:将问题和检索的内容生成提示词喂给大模型,利用大模型的总结能力返回答案。
1.3. 实践RAG应用
1、基于公司的制度文件创建RAG应用,步骤如下:
-
解析文本文件
-
创建索引
-
创建提问引擎(设置流式输出)
-
输入问题并输出答案
# 导入依赖
from llama_index.embeddings.dashscope import DashScopeEmbedding,DashScopeTextEmbeddingModels
from llama_index.core import SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.openai_like import OpenAILike
# 这两行代码是用于消除 WARNING 警告信息,避免干扰阅读学习,生产环境中建议根据需要来设置日志级别
import logging
logging.basicConfig(level=logging.ERROR)
print("正在解析文件...")
# LlamaIndex提供了SimpleDirectoryReader方法,可以直接将指定文件夹中的文件加载为document对象,对应着解析过程
documents = SimpleDirectoryReader('./docs').load_data()
print("正在创建索引...")
# from_documents方法包含切片与建立索引步骤
index = VectorStoreIndex.from_documents(
documents,
# 指定embedding 模型
embed_model=DashScopeEmbedding(
# 你也可以使用阿里云提供的其它embedding模型:https://help.aliyun.com/zh/model-studio/getting-started/models#3383780daf8hw
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
))
print("正在创建提问引擎...")
query_engine = index.as_query_engine(
# 设置为流式输出
streaming=True,
# 此处使用qwen-plus模型,你也可以使用阿里云提供的其它qwen的文本生成模型:https://help.aliyun.com/zh/model-studio/getting-started/models#9f8890ce29g5u
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"),
is_chat_model=True
))
print("正在生成回复...")
streaming_response = query_engine.query('我们公司项目管理应该用什么工具')
print("回答是:")
# 采用流式输出
streaming_response.print_response_stream()
2、RAG程序优化,保存和加载索引
由于创建索引的时间比较长,如果提前创建索引并保存到本地,则可以提升大模型回答的速度。
# 将索引保存为本地文件
index.storage_context.persist("knowledge_base/test")
print("索引文件保存到了knowledge_base/test")
# 将本地索引文件加载为索引
from llama_index.core import StorageContext,load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="knowledge_base/test")
index = load_index_from_storage(storage_context,embed_model=DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
))
print("成功从knowledge_base/test路径加载索引")
封装:
from chatbot import rag
# 引文在前面的步骤中已经建立了索引,因此这里可以直接加载索引。如果需要重建索引,可以增加一行代码:rag.indexing()
index = rag.load_index(persist_path='./knowledge_base/test')
query_engine = rag.create_query_engine(index=index)
rag.ask('我们公司项目管理应该用什么工具', query_engine=query_engine)
2. RAG工作流程优化
rag的工作流程如下:
-
解析与切片
-
向量存储
-
检索召回
-
生成答案
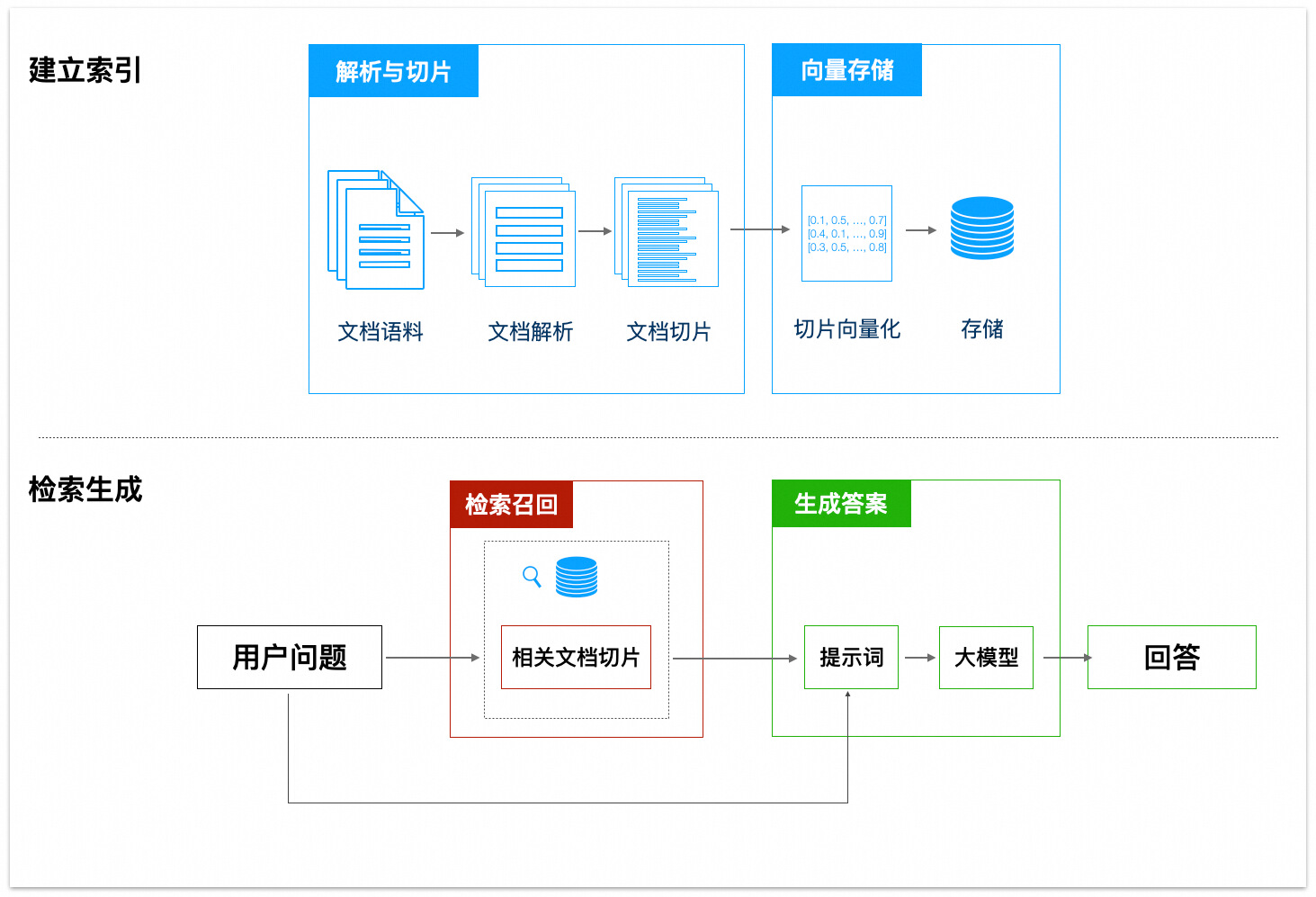
RAG各个环节优化策略
2.1. 文档准备阶段
2.2. 文档解析与切片阶段
2.2.1. 问题分类及改进策略
2.2.2. 借助工具解析pdf到markdown
2.2.3. 使用多种文档切片方法
-
Token切片
-
句子切片
-
句子窗口切片
-
语义切片
-
markdown切片
2.3. 切片向量化与存储阶段
文档切片后需要建立索引,可以使用嵌入(Embedding)模型将切片向量化,并存储到向量数据库中。
2.3.1. 了解Embedding与向量化
Embedding模型将文本转换为高维向量,向量之间夹角越小说明相似度越高。
2.3.2. 选择合适的Embedding模型
不同的Embedding模型对相同文字得到的向量可能完全不同,越新的Embedding模型其表现越好。在实践中,单纯升级Embedding模型就可以显著提升检索质量。
2.3.3. 选择合适的向量数据库
向量存储方案从简单到复杂如下:
-
内存向量存储:优点快速上手,开发测试;缺点数据无法持久化,受限于内存大小。 -
本地向量数据库:例如Milvus、Qdrant 等。这些数据库提供了数据持久化和高效检索能力。优点是功能完整、可控性强;缺点是需要自行部署维护。 -
云服务向量存储:例如阿里云的向量检索服务(DashVector),向量检索服务 Milvus 版,已有数据库的向量能力。优点是按量付费,成本可控,无需运维。
选择建议:
-
开发测试选择内存向量存储
-
小规模应用选择本地向量数据库
-
生产环境使用云服务。
2.4. 向量召回阶段
2.3.1. 问题改写
-
使用大模型扩充问题
-
将单一查询改为多步查询
-
用假设文档来增强检索
2.3.2. 提取标签增强检索
在向量检索的基础上我们可以增加标签过滤:
-
建立索引时,从文档切片中提取结构化标签
-
检索时,从用户问题中提取对应标签进行过滤
2.2.3. 重排序
从向量数据库中检索出20条文档切片,通过文本排序模型进行重新排序,删选出最相关的3条信息。
2.5. 生成答案阶段
大模型生成的答案不及预期,可以通过以下方式解决:
-
选择合适的大模型
-
充分优化提示词模板:明确要求不编造答案;添加内容分隔标记;根据问题类型调整模板。
-
调整大模型参数
-
调优大模型
参考:
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.