大模型微调
1. 模型如何学习
1.1. 机器学习-通过数据寻找规律
假设有个规则编写成函数的形式,例如:f(x)=ax。机器学习的目标就是帮助你通过数据(训练集)来尝试找到 a 这些参数值,这一过程被称为训练模型。
1.2. Loss Function & Cost Function - 量化评估模型表现
为了评估f(x)=ax中的a是否合适,我们可以通过损失函数和代价函数来判断。
1.2.1. Loss Function 损失函数
你可以用训练集的每一个样本$x_i$对应的实际结果值 $y_i$,与模型预测结果值 $f(x_i)$相减,来评估模型在$x_i,y_i$这一条数据上的表现。这个评估误差的函数被称为 Loss Function(损失函数,或误差函数):$L(y_i, f(x_i)) = y_i - ax_i$。因为差值有正负,因此我们通过差值的平方的方式来计算损失函数,$L(y_i, f(x_i)) = (y_i - ax_i)^2$。同时,平方值能够放大误差的影响,有利于你找到最合适的模型参数。
在实际应用中,对于不同的模型,可能会选择不同的计算方法来作为 Loss Function。
1.2.2. Cost Function 代价函数
为了评估模型在整个训练集上的表现,你可以计算所有样本的损失平均值(即均方误差,Mean Squared Error,MSE)。这种用于评估模型在所有训练样本上的整体表现的函数,被称为 Cost Function(代价函数,或成本函数)。
对于包含 m 个样本的训练集,代价函数可以表示为:$J(a) = \frac{1}{m} \sum_{i=1}^{m} (y_i - ax_i)^2$。
在实际应用中,对于不同的模型,也可能会选择不同的计算方法来作为 Cost Function。
有了 Cost Function,寻找模型合适的参数的任务,就可以等效为寻找 Cost Function 最小值(即最优解)的任务。找到 Cost Function 的最小值,意味着该位置的参数 a 取值,就是最合适的模型参数取值。
实际工作中,我们将代价函数和损失函数统一称为损失函数。
1.3. 梯度下降法
一种常见的梯度下降算法实现是,先在曲面(或曲线)上随机选择一个起点,然后通过不断小幅度调整参数,最终找到最低点(对应最优参数配置)。
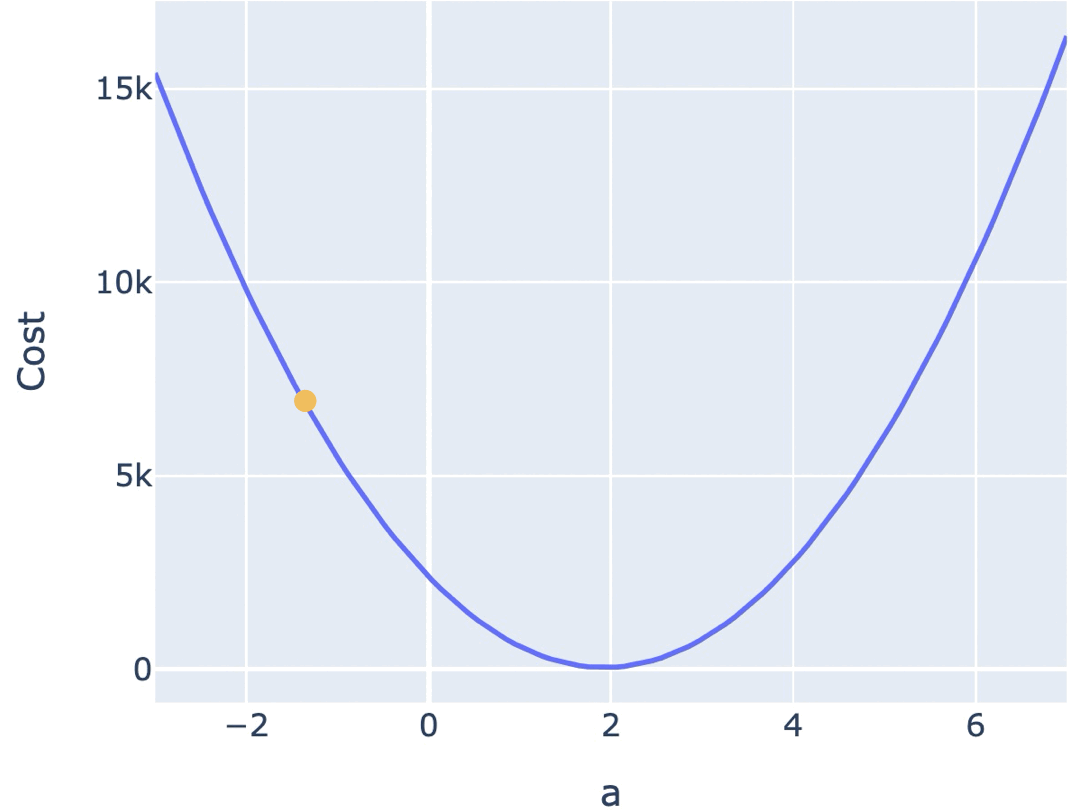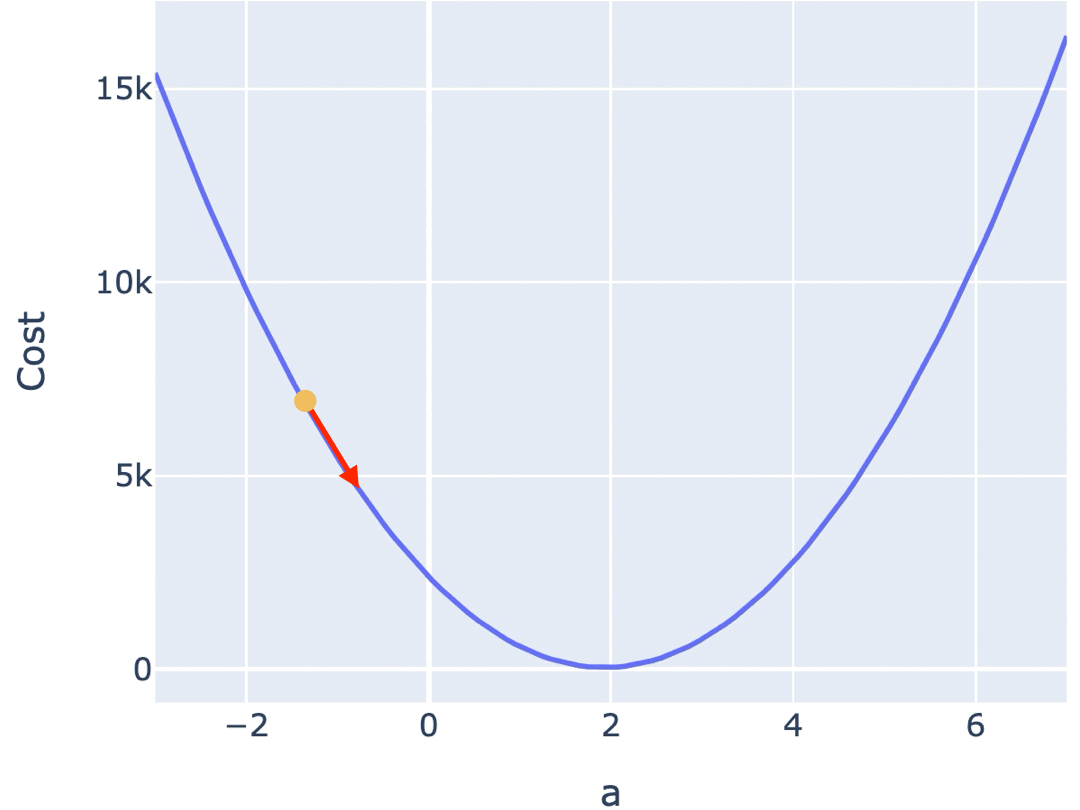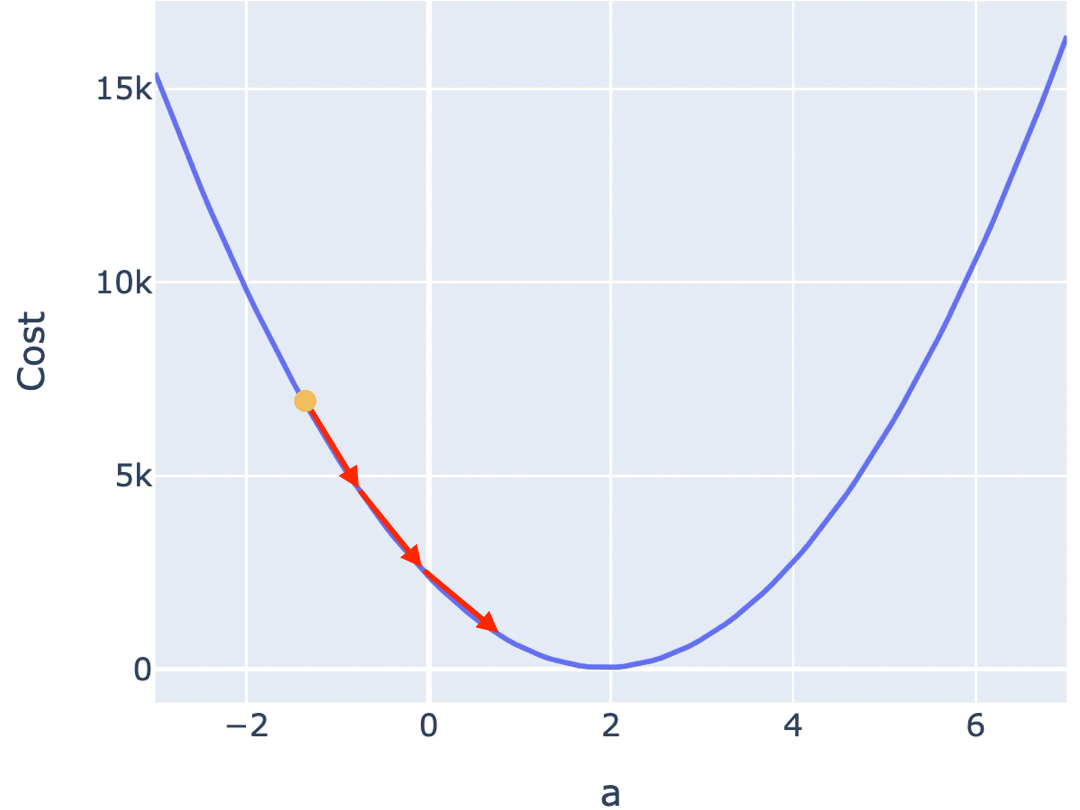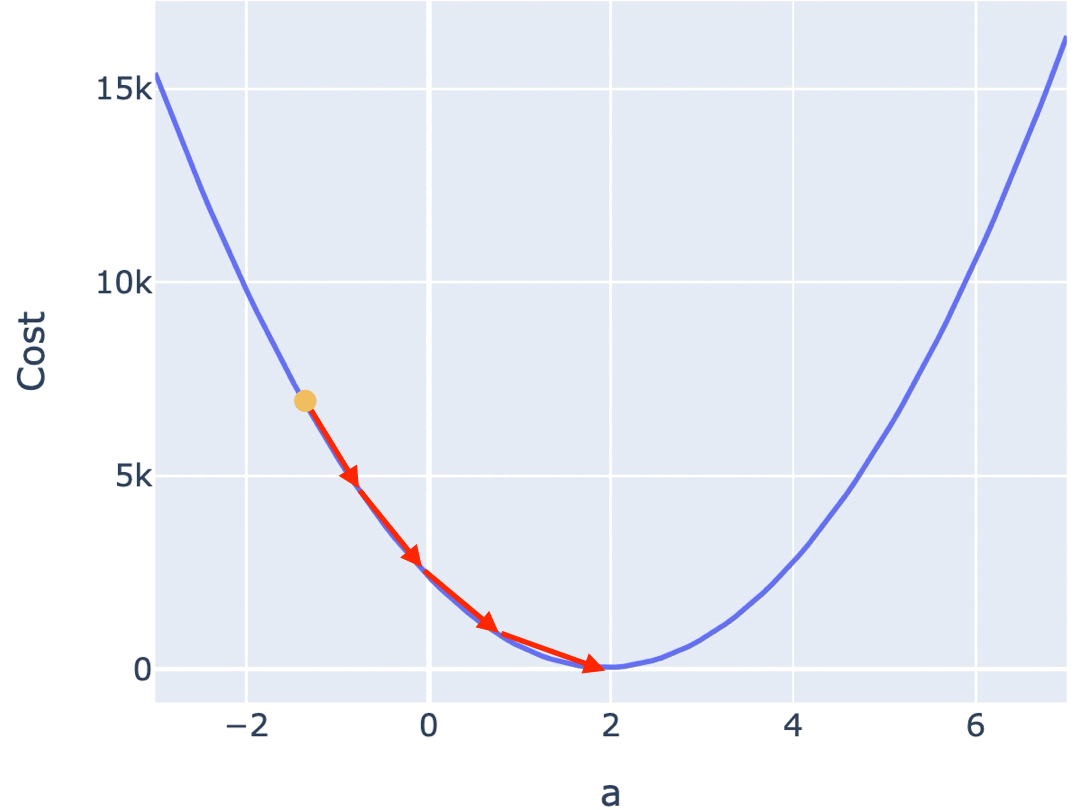
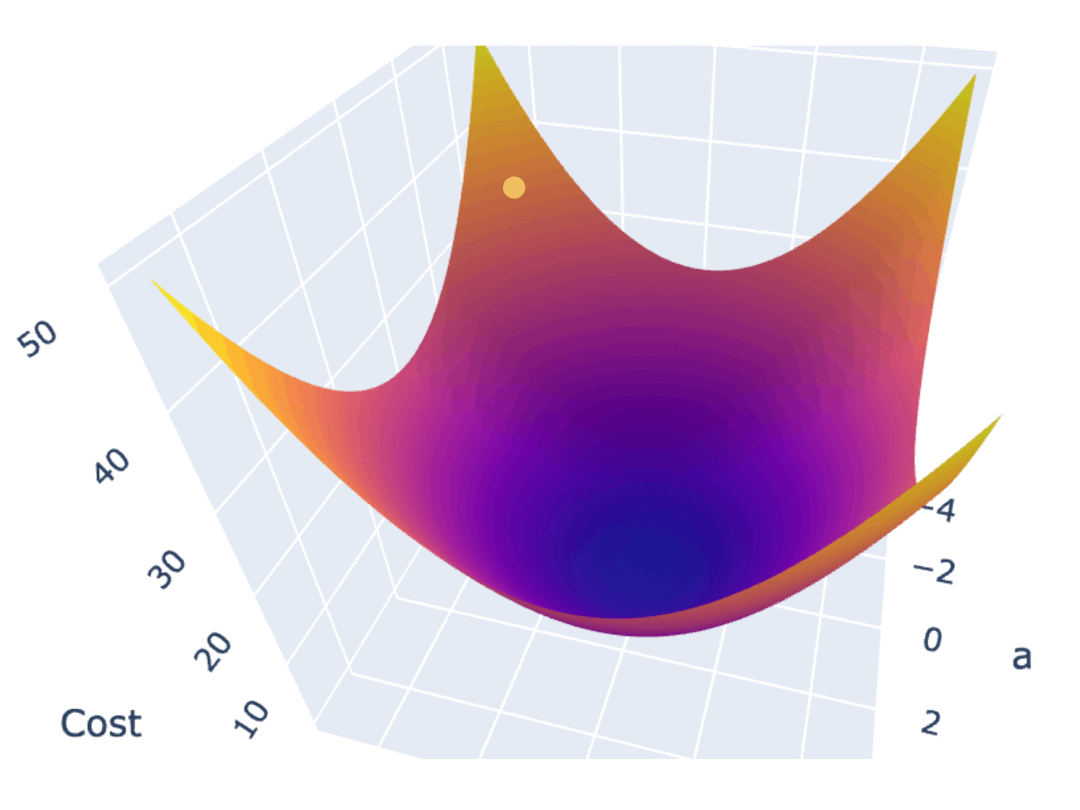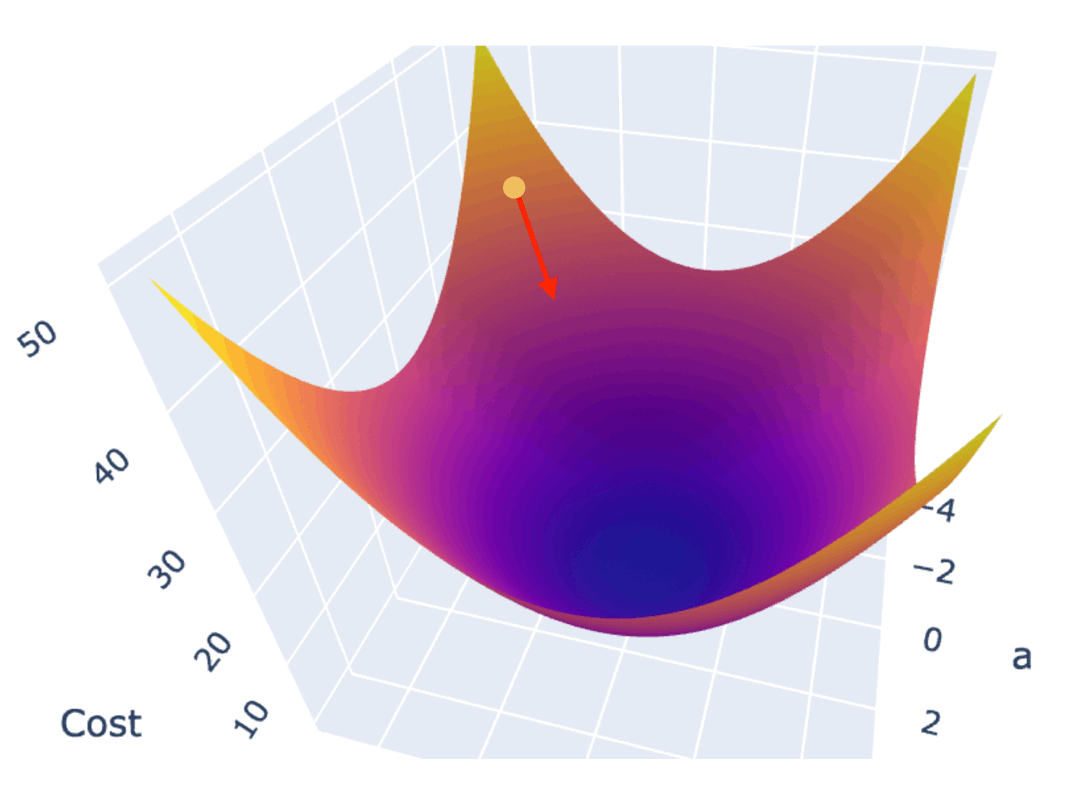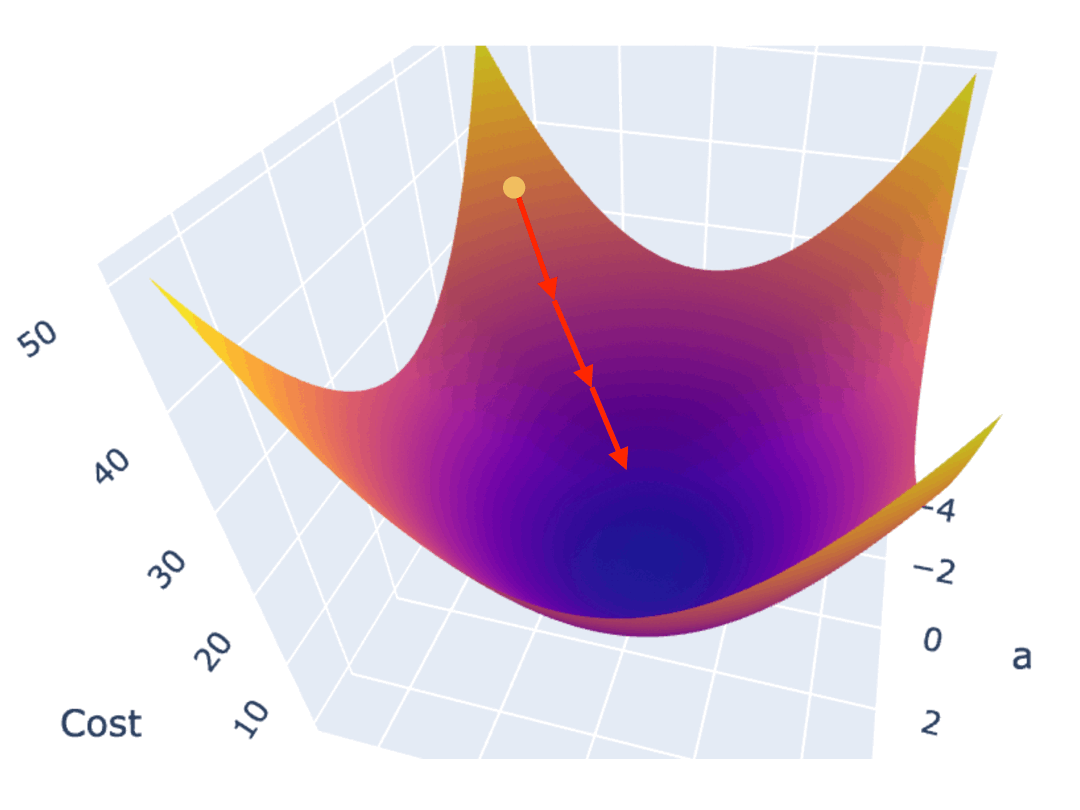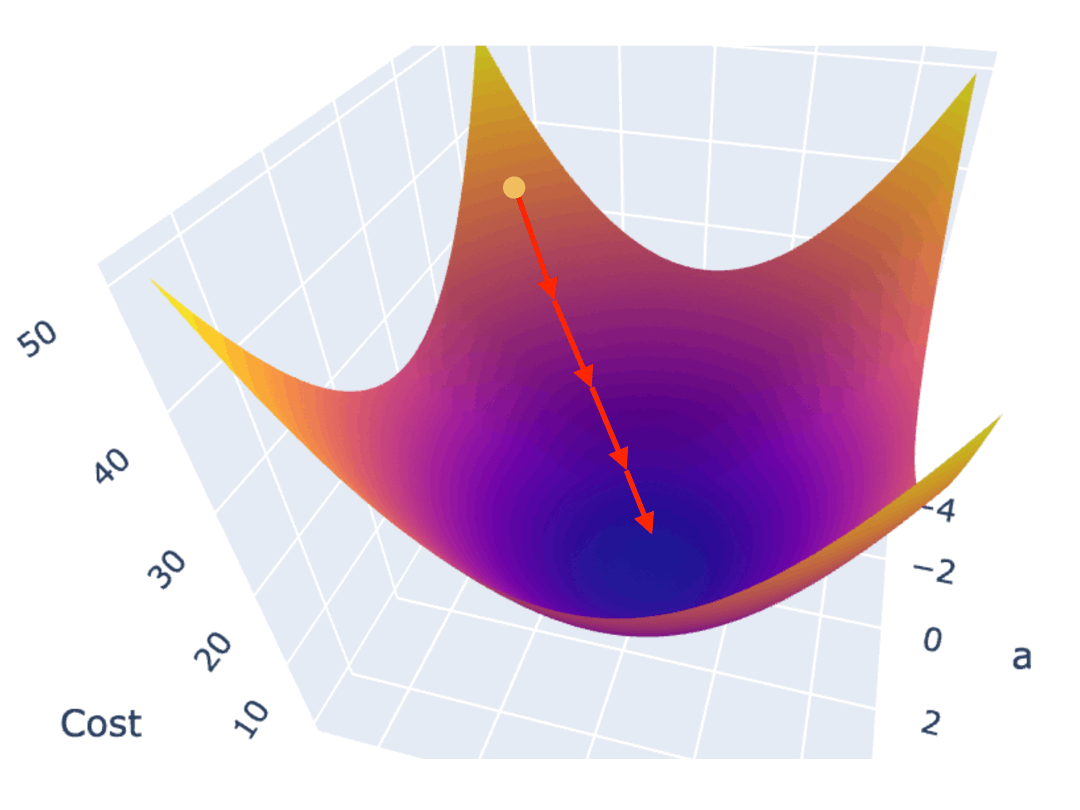
训练模型时,你需要训练程序能自动地不断调整参数,最终让 Cost Function 的值逼近最低点。所以梯度下降算法,需要能自动地控制两点:
-
调整参数的方向
-
调整参数的幅度
1.3.1. 调整参数的方向
1.3.2. 调整参数的幅度
如果按照固定的步长调整参数,那么可能导致在最低点附近反复震荡,无法逼近最低点。越接近最低点,斜率越小,因此可以使用当前位置的斜率作为调整的幅度。针对损失函数斜率非常陡峭,也可能反复在最低点震荡,因此可以将斜率再乘以一个系数,我们称之为学习率(Learning rate)。
-
过低的学习率,会导致找到合适的参数速度变慢,消耗更多的资源和时间。
-
过高的学习率,会导致跳过最优解,最终找不到最低点。
1.4. 模型训练用的参数
batch size
较大的batch size会加速训练过程,但对资源消耗更大,过大的batch size可能导致模型泛化性能下降的问题
eval steps
因为训练集数量大,因此一般不会对训练集完整迭代后进行评估,而是间隔多少个训练步骤后评估,这个间隔步骤称为eval_steps。
epoch
对训练集一个完整的迭代称为epoch,
-
过小的epoch值会导致训练结束还没找到最优参数。
-
过大的epoch值会导致训练时间长以及资源浪费。
寻找合适epoch常用早停法(early stopping):在训练过程中定期评估模型表现,当模型不再提升则自动停止训练。
2. 高效微调技术
2.1. 预训练和微调
模型训练的本质就是寻找最合适的参数组合。最开始下载好的模型就是预训练好的参数组合。微调则是在此基数上进一步调整参数,以适应你的目标任务。
预训练与微调的主要区别
| 特性 | 预训练 | 微调 |
|---|---|---|
| 目标 | $ $ 学习通用特征 | 适应特定任务 |
| 数据 | 大规模通用数据 | 小规模任务相关数据 |
| 训练方法 | 自监督/无监督 | 有监督 |
| 参数更新 | 所有参数可训练 | 部分或全部参数可训练 |
| 应用场景 | 基础模型构建 | 特定任务优化 |
2.2. LoRA微调
LoRA(Low-Rank Adaptation)低秩适应微调是现在最常用的微调方法。
3. 微调实战
训练的三套题目:
-
训练集:课程练习题,训练损失越小说明模型在练习册上表现更好。 -
验证集:模拟考试题,验证损失越小说明在模拟考试中表现越好。 -
测试题:考试真题,模型在测试集上的准确率用于评估模型最终表现。
训练的三个状态:
-
训练损失不变,甚至变大:说明训练失败。
-
训练损失和验证损失都在下降:说明模型欠拟合,模型学习不充分,在训练集上表现不好。
-
训练损失下降但验证损失上升:说明模型过拟合,模型在训练集表现好(背题),在新数据表现差。
如何调参:
-
训练损失和验证损失增大,说明训练失败,则调低学习率,慢慢学习。
-
训练欠拟合,说明学习不够,增加学习批大小(batch_size),增加学习次数(epochs)。
-
训练过拟合,说明在背题,降低学习次数(epoch),增加LoRA的秩。
-
训练成功:训练损失基本不减小,验证损失也不减小甚至还略微升高。
参数:
-
学习率(learning_rate):训练失败,调低学习率。
-
LoRA的秩(lora_rank):训练过拟合,增大lora_rank。
-
数据集学习次数(num_tarin_epochs):训练欠拟合,增加学习次数。
-
batch_size:训练欠拟合,说明学习不够,增加学习批大小。
参考:
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.