大模型原理
1. 大模型是如何工作的
1.1. 大模型的问答工作流程
大模型问答工作流程主要有以下五个阶段
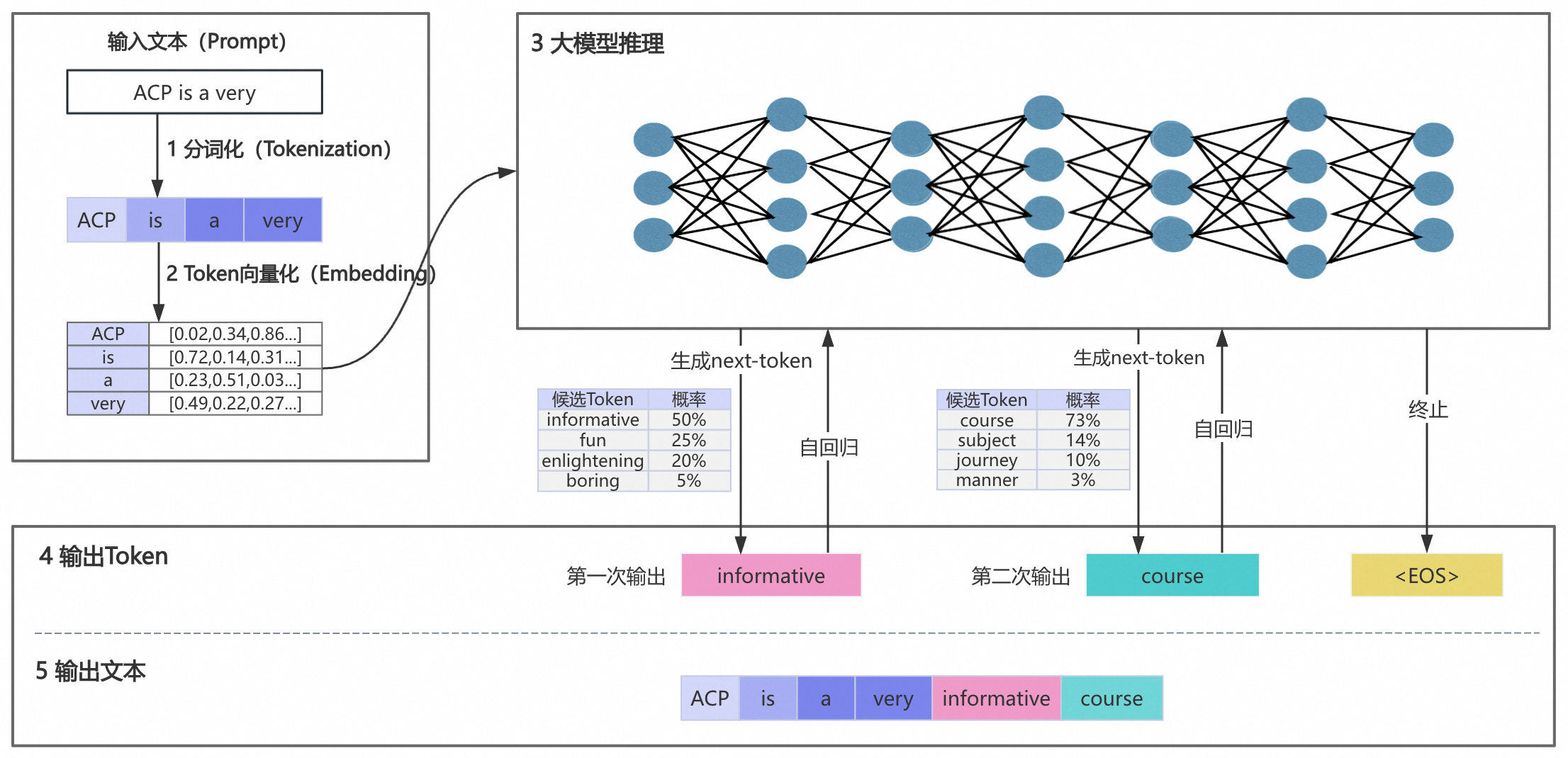
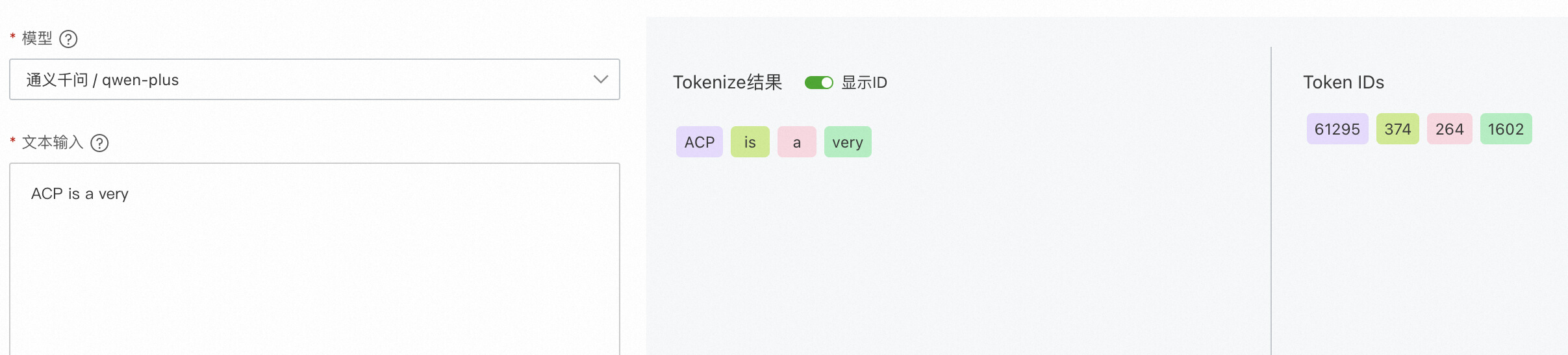
1.1.1. 输入文本分词化
分词(Token)是大模型处理文本的基本单元,通常是词语、词组或者符号。我们需要将“ACP is a very”这个句子分割成更小且具有独立语义的词语(Token),并且为每个Token分配一个ID。
1.1.2. Token向量化
将分词(Token)转换为数字使得其被计算机理解,即将每个Token转换为固定维度的向量。
1.1.3. 大模型推理
大模型通过已有数据的训练,它会计算所有可能的token的概率,并选出下一个输出的token。当大模型回答私域知识,即不涉及训练的内容的时候,则无法回答出问题。
1.1.4. 输出Token
大模型会根据token的概率来随机进行挑选,即问题完全相同,每次的回答都可能略有不同。为了控制问题的随机性,可以通过temperature和top_p来调整。
1.1.5. 输出文本
循环第三和第四的步骤,直到输出特殊的Token(如EOS,end of sentence)或输出的长度达到阈值,从而结束回答,并输出所有的内容。也可以使用流式输出,即预测下一个token后立即返回给用户。
1.2. 影响大模型内存生成的随机性参数
大模型随机性和多样性的2个重要的参数是temperature和top_p。
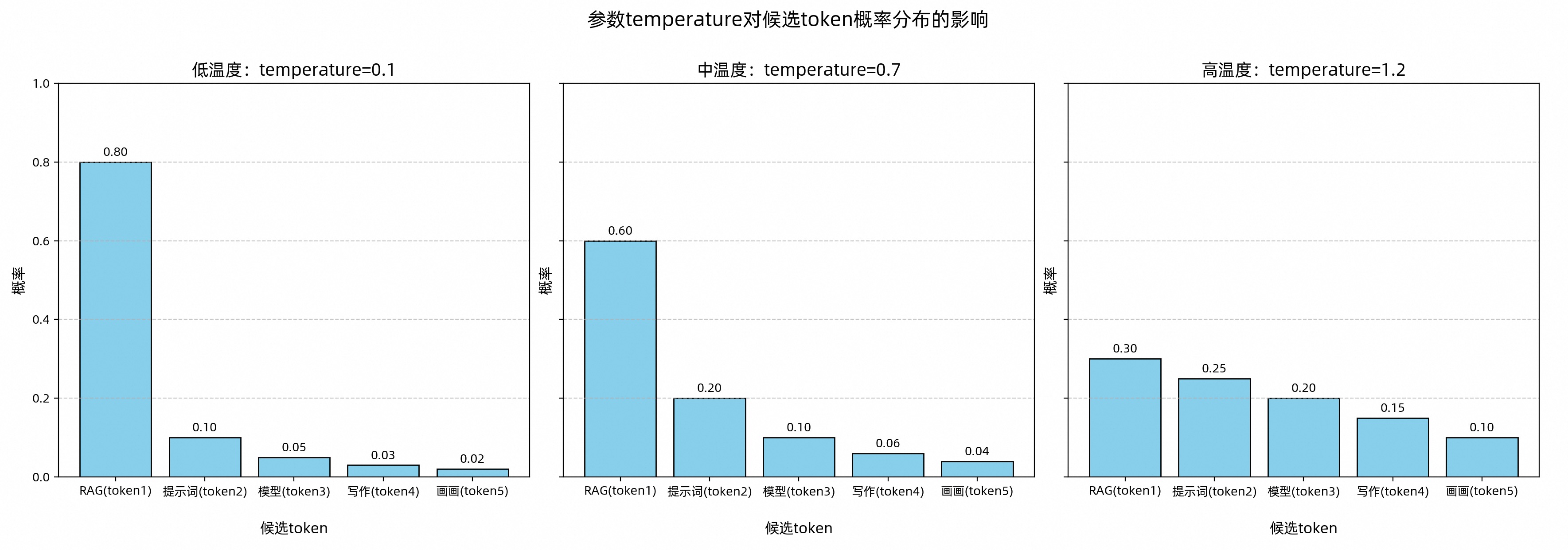
1.2.1. temperature:调整候选Token集合的概率分布
temperature是一个调节器,它通过改变候选Token(next-token)的概率分布,影响大模型的内容生成。
针对不同使用场景,可参考以下建议设置 temperature 参数:
-
明确答案(如生成代码):调低温度。
-
创意多样(如广告文案):调高温度。
-
无特殊需求:使用默认温度(通常为中温度范围)。
需要注意的是,当 temperature=0 时,虽然会最大限度降低随机性,但无法保证每次输出完全一致。温度值越高,模型生成的内容更具变化和多样性。可参考temperature的底层算法实现。
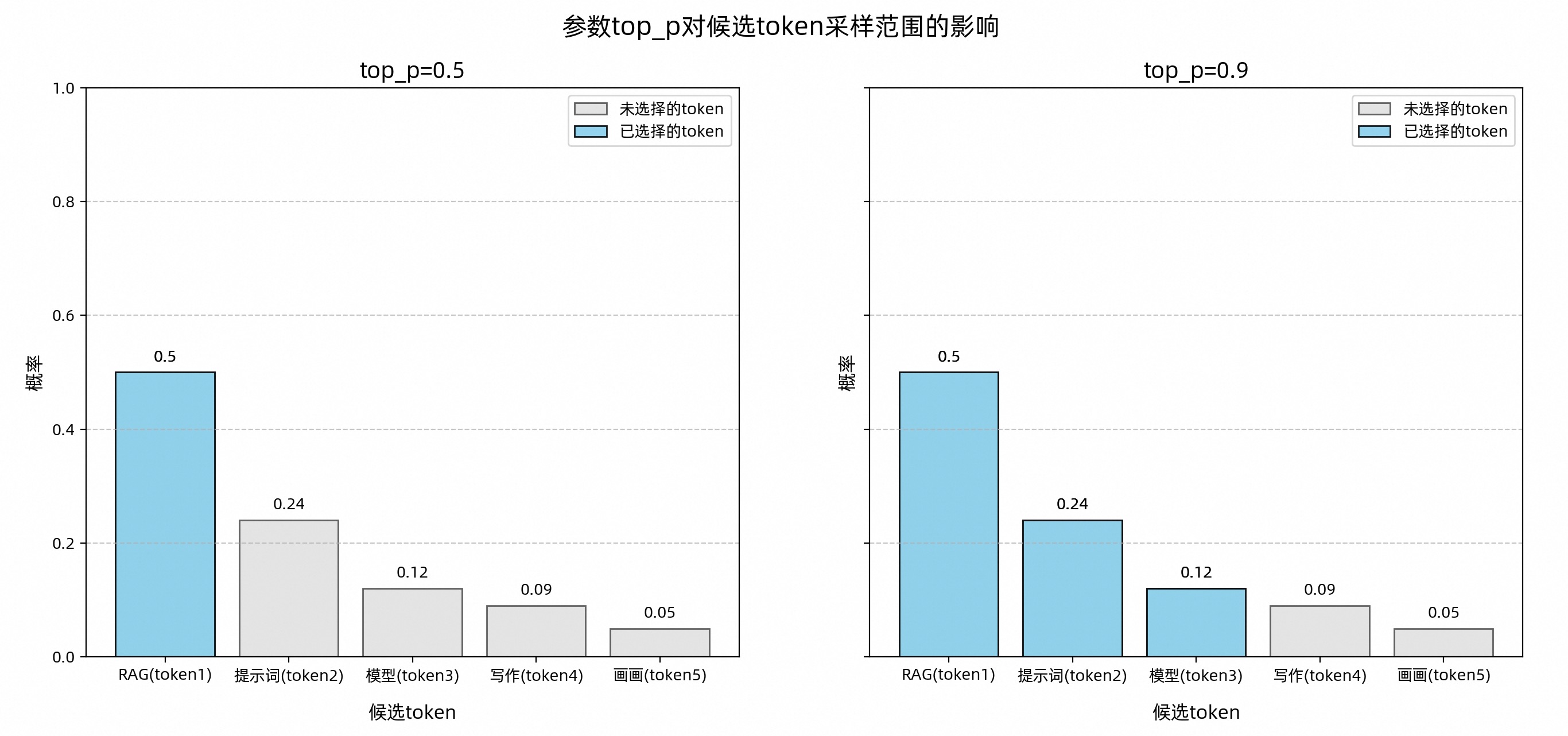
1.2.2. top_p:控制候选Token集合的采样范围
top_p 是一种筛选机制,用于从候选 Token 集合中选出符合特定条件的“小集合”。具体方法是:按概率从高到低排序,选取累计概率达到设定阈值的 Token 组成新的候选集合,从而缩小选择范围。
top_p值对大模型生成内容的影响可总结为:
-
值越大 :候选范围越广,内容更多样化,适合创意写作、诗歌生成等场景。
-
值越小 :候选范围越窄,输出更稳定,适合新闻初稿、代码生成等需要明确答案的场景。
-
极小值(如 0.0001):理论上模型只选择概率最高的 Token,输出非常稳定。但实际上,由于分布式系统、模型输出的额外调整等因素可能引入的微小随机性,仍无法保证每次输出完全一致。
1.2.3. 如何使用temperature和top_p
为了确保生成内容的可控性,建议不要同时调整temperature和top_p,可以通过控制变量法,逐步调整其中一个参数来实现微调。在其他的大模型也会增加其他参数来控制内容的多样性,例如通义千问模型的参数seed。具体可以参考对应的API说明。
2. 让大模型回答私域知识
由于大模型是根据已知的知识训练成的,因此他无法回答未训练的知识,例如私域知识。好比人无法回答他所不知道的事情。如何让大模型回答私域的知识,就是把私域的知识喂给它。
2.1. 初步方案:在提示词中喂知识
例如:
在已知的文档中找到跟问题相关的信息,然后放入prompt中一起请求大模型接口。
user_question = "我是软件一组的,请问项目管理应该用什么工具"
knowledge = """公司项目管理工具有两种选择:
1. **Jira**:对于软件开发团队来说,Jira 是一个非常强大的工具,支持敏捷开发方法,如Scrum和Kanban。它提供了丰富的功能,包括问题跟踪、时间跟踪等。
2. **Microsoft Project**:对于大型企业或复杂项目,Microsoft Project 提供了详细的计划制定、资源分配和成本控制等功能。它更适合那些需要严格控制项目时间和成本的场景。
在一般情况下请使用Microsoft Project,公司购买了完整的许可证。软件研发一组、三组和四组正在使用Jira,计划于2026年之前逐步切换至Microsoft Project。
"""
response = get_qwen_stream_response(
user_prompt=user_question,
# 将公司项目管理工具相关的知识作为背景信息传入系统提示词
system_prompt="你负责教育内容开发公司的答疑,你的名字叫公司小蜜,你要回答学员的问题。"+ knowledge,
temperature=0.7,
top_p=0.8
)
for chunk in response:
print(chunk, end="")
上述的方式会引入新的问题,比如你无法把所有的数据都喂给大模型,会带来一些问题:
-
效率低:上下文越长,大模型处理所需的时间就越长,导致用户等待时间增加。
-
成本高:大部分模型是按输入和输出的文本量计费的,冗长的上下文意味着更高的成本。
-
信息干扰:如果上下文中包含了大量与当前问题无关的信息,就像在开卷考试时给了考生一本错误科目的教科书,反而会干扰模型的判断,导致回答质量下降。
因此如何将更精准的信息喂给大模型,就是上下文工程(Context Engineering)。
2.2. 上下文工程
上下文工程的核心技术包括:
-
RAG(检索增强生成):从外部知识库检索信息,为模型提供精准的回答依据。
-
Prompt(提示词工程):精心设计指令,精确引导模型的思考方式和输出格式。
-
Tool(工具使用):赋予模型外部工具,例如实时搜索获取在线信息。
-
Memory(记忆机制):为模型建立长短期记忆,使其可以在连续的对话中理解历史上下文。
3. 推理大模型
推理模型相较于通用大模型多出了“思考过程”,就像解数学题时有人会先在草稿纸上一步步推导,而不是直接报答案,减少模型出现“拍脑袋”的错误。
| 维度 | 推理模型 | 通用模型 |
|---|---|---|
| 设计目标 | 专注于逻辑推理、多步问题求解、数学计算等需要深度分析的任务 | 面向通用对话、知识问答、文本生成等广泛场景 |
| 训练数据侧重 | 大量数学题解、代码逻辑、科学推理数据集增强推理能力 | 覆盖百科、文学、对话等多领域海量数据 |
| 典型输出特征 | 输出包含完整推导步骤,注重逻辑链条的完整性 | 输出简洁直接,侧重结果的自然语言表达 |
| 响应速度 | 复杂推理任务响应较慢(需多步计算) | 常规任务响应更快(单步生成为主) |
如何选择:
- 明确的通用任务:对于明确定义的问题,通用模型一般能够很好地处理。
- 复杂任务:对于非常复杂的任务,且需要给出相对更精确和可靠的答案,推荐使用推理模型。这些任务可能有:
- 模糊的任务:任务相关信息很少,你无法提供模型相对明确的指引。
- 大海捞针:传递大量非结构化数据,提取最相关的信息或寻找关联/差别。
- 调试和改进代码:需要审查并进一步调试、改进大量代码。
- 速度和成本:一般来说推理模型的推理时间较长,如果你对于时间和成本敏感,且任务复杂度不高,通用模型可能是更好的选择。
参考:
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.